
Industry 4.0 promises data-driven decisions, predictive maintenance and complete transparency of production processes. The reality in many factories is different: Sensors deliver raw data that is barely usable. IT teams struggle with integration. And in the end, data scientists are deployed to clean up data that should actually arrive clean.
The problem is not the hardware. It’s where and how data is processed – and what that costs.
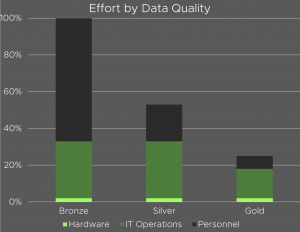
The real cost problem: IT operations and personnel
Anyone looking at the actual cost structure of industrial data quality quickly realizes that hardware costs are a comparatively small item. The biggest cost drivers are IT operations and personnel – and both scale strongly with the quality of the source data.
Imagine three levels of data – bronze, silver and gold:
- Bronze – raw data: Directly from the sensor, unstructured, full of noise. Hardly suitable for further processing. The effort for IT operations and personnel to turn this data into something usable is enormous.
- Silver – Cleaned data: Filtered and normalized, but not yet curated. Operating expenses are reduced by around half compared to bronze – but remain significant.
- Gold – Curated and aggregated data: Structured, contextualized, directly analyzable. The total effort required is only around a quarter of the bronze level.
The worse the initial data, the more effort is required for cleansing, integration and ongoing maintenance – often a multiple of the pure hardware costs. The path from bronze to gold therefore not only means better data, but also a fundamental reduction in operating costs.
The key question is: How do you achieve gold quality – quickly, reliably and without interrupting ongoing operations?
The answer: AI directly in the data flow
Traditional approaches answer this question with cloud infrastructure, data warehouses or downstream processing pipelines. This means latency, dependencies on external services, data protection risks and – above all – high running costs for IT operations and personnel.
EdgeBrain takes a different approach.
EdgeBrain is a deterministic logic module that plugs and plays directly into the system’s data flow. It refines raw data into curated gold data in real time – locally, latency-free and completely under the operator’s control.
The principle is simple: instead of feeding data out of the system, processing it somewhere and sending the result back, all the intelligence happens where the data is generated – directly in the flow.
How EdgeBrain works: three steps
1. Signal received
EdgeBrain is placed directly in the data flow of the plant – at the point where raw data is generated, even before it reaches any downstream system. The existing infrastructure, including controllers, sensors and networks, remains completely unchanged.
2. Dedicated intelligence processes in real time
Instead of a general-purpose computer, a dedicated computing unit takes over signal processing – comparable to a specialized production cell that knows exactly one task and executes it with absolute precision, without delay and without external dependencies. The result is deterministic: reproducible at any time, auditable and completely independent of cloud connections or network availability.
3. Added value immediately usable
The result is curated, aggregated data – directly usable for MES, ERP, quality assurance or analytics applications. The downstream systems no longer receive raw data that they have to interpret themselves, but structured information with defined semantics.
What this means for companies
The consequences of this approach are measurable:
Less operating costs. Because gold data no longer requires downstream cleansing, a large proportion of the IT and personnel costs previously incurred for data maintenance and integration are eliminated. In practice, this means a reduction in total expenditure of up to 75% compared to operating with raw data.
Lower energy consumption. Local processing directly at the plant is up to 90% more energy-efficient than cloud-based AI infrastructure. No servers, no cooling, no data transfer via wide area networks.
No standstill during retrofitting. EdgeBrain is integrated into the existing infrastructure as a plug-and-play module. Integration does not require any production stoppages, reprogramming of control systems or complex IT projects.
Full data sovereignty. As processing takes place locally and no data leaves the factory, cloud lock-in, data protection risks and dependencies on external service providers are eliminated.
From bronze to gold – without detours
The idea behind EdgeBrain is not new: in data processing, it has long been known that quality should be assured at the point of origin – not at the end of a long processing chain. In industry, however, this has hardly been technically feasible until now. The requirements for real-time, robustness and integration into existing systems were too great.
With EdgeBrain, this approach is now available on an industrial scale. As a compact, robust module that works in the harsh reality of a production environment – not in the laboratory.
The result: raw data is no longer managed, but refined. Directly at the plant. From bronze to gold – without detours.
Would you like to see how EdgeBrain works in your system? Arrange a demo now: info@dejonge.ai